Amazon S3는 Amazon Web Services에서 제공하는 클라우드 스토리지. 용량과 트래픽에 따라 과금되는 무게 과금 제의 웹 서비스입니다. 적당히 용량에서도 통신 량이 많아야 저렴한 가격으로 이용할 수 있기 때문에 백업 용도로 아주 궁합이 좋다.
지금까지 VPS를 백업 용도로 이용하고 있었지만, Amazon S3라도 간단하게 백업 시스템을 구축 할 수 있기 때문에 앞으로 Web 사이트 등의 백업을 실시하고 싶다고 생각하고있는 분에 Amazon S3에 백업하는 방법을 소개하고 싶다.
AWS (Amazon Web Services)에 등록
Amazon S3를 사용하려면 먼저 AWS 계정 등록 할 필요가있다. 등록 화면이 영어로 헤매고 버렸지 만, 본 기사를 쓸 때, 공식적으로 알기 쉽게 등록 절차가 정리되어있는 것을 발견했다. 아직 등록되지 않은 분은 아래를 참고로 등록되면 좋겠다.
버킷 만들기
Amazon S3는 일반적인 렌탈 서버와 달리 FTP로 파일이나 디렉토리를 업로드하는 것이 아니라 전용 명령에서 "양동이"라는 위치에 파일이나 디렉토리를 업로드하고 "개체"로 저장한다. 버킷은 AWS 관리 화면에서 작성한다.
AWS 관리 화면에서 "계정 / 콘솔> AWS Management Console"고 가면 서비스의 목록이 표시되므로 'S3'를 클릭한다.
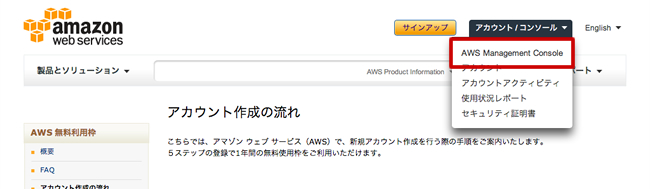
AWS Management Console
S3 관리 화면이 열리면 여기에서 "Create Backet"를 클릭 임의의 버킷 이름을 입력 지역 (어느 서버를 사용하는지)를 선택하여 버킷을 생성한다.
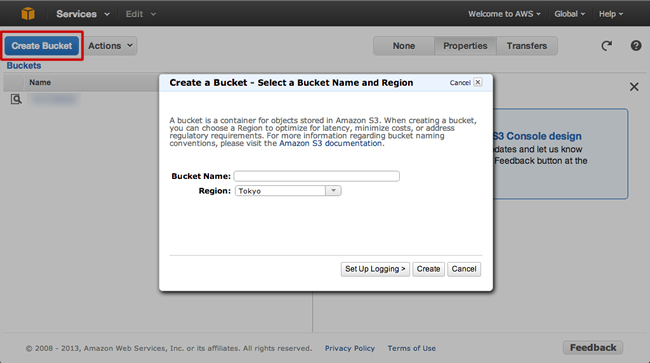
버킷 만들기
키의 취득
Amazon S3의 조작에 자신의 명령을 사용한다. 그 때, 올바른 이용자 가지 식별을 위해 "키"가 필요하다. AWS 관리 화면에서 "계정 / 콘솔> 보안 인증서"로 가서 키를 가져옵니다.
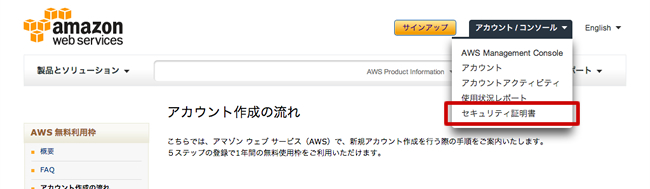
보안 인증서
액세스 키를 생성하면 "액세스 키 ID '와'시크릿 키 '가 표시되므로 삼가 해 두자.
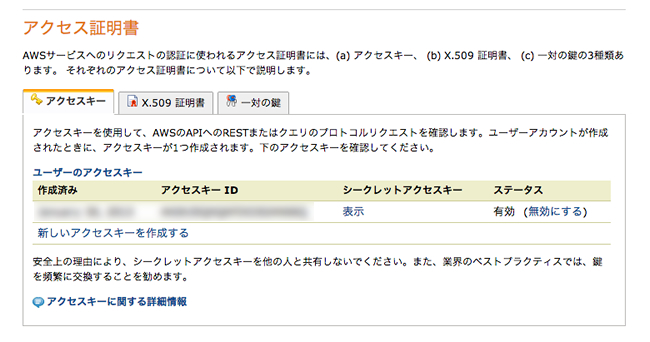
액세스 키 ID 및 보안 액세스 키
s3sync 설치
Amazon S3에서 데이터 전송 및 동기화를 수행하려면 s3sync는 rsync와 같은 명령을 사용한다. s3sync를 사용하려면 ruby가 필요하므로 ruby 설치도 실시한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # ruby 설치$ sudo yum install ruby# s3sync을 다운로드 압축$ wget http : // s3 .amazonaws.com / ServEdge_pub / s3sync / s3sync . tar .gz$ tar zvfx s3sync. tar .gz# config 파일을 생성# s3config.yml 위치는 환경 변수 · $ S3CONF / * $ HOME / .s3conf / · / etc / s3conf / 중$ sudo mkdir / etc / s3conf /$ sudo cp s3sync / s3config .yml.example / etc / s3conf / s3config .yml$ sudo vi / etc / s3conf / s3config .yml##############################aws_access_key_id : xxxxx # 키 ID를 작성aws_secret_access_key : xxxxx # 비밀 키를 작성S3SYNC_NATIVE_CHARSET : UTF-8AWS_CALLING_FORMAT : SUBDOMAIN # 지역이 미국 이외의 경우는 필요############################## |
s3cmd 설치
s3cmd는 Amazon S3를 조작하기위한 명령어. 이번에는 s3sync에서 백업 데이터의 업로드를 수행하지만, 용량이 증가하는 것을 방지하기 위해 오래된 업로드 데이터를 s3cmd에서 삭제하기로한다.
s3cmd은 yum에도 설치할 수 있고, 공개 된 zip 파일의 압축을 풀고 그대로 이용할 수도있다. 간단한 yum으로 설치하는 것을 권장하지만, 렌탈 서버 등 yum을 사용할 수없는 환경에서는 zip 파일을 다운로드하여 설치하게된다. 여기에서는 렌탈 서버의 예로 「벚꽃의 렌탈 서버」의 경우 설정을 적어 둔다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # yum으로 설치하는 경우$ cd / etc / yum .repos.d /$ wget http : // s3tools .org / repo / RHEL_6 / s3tools .repo$ sed -i -es / enabled = 1 / enabled = 0 / s3tools.repo$ yum install s3cmd --enablerepo = s3tools# zip 파일을 다운로드하여 설치의 경우 (python이 필요)$ mkdir -p $ HOME / local / python$ wget http : // peak .telecommunity.com / dist / virtual-python .py$ python virtual-python.py --prefix = $ HOME / local / python - v$ vi .cshrc############################### 다음을 추기set path = ($ HOME / local / python / bin $ path)set PYTHONPATH = ($ HOME / local / python )############################### .cshrc 다시 읽기 위해 로그 아웃하고 로그인$ wget http : // peak .telecommunity.com / dist / ez_setup .py$ python ez_setup.py$ wget http : // downloads .sourceforge.net / project / s3tools / s3cmd / 1 .1.0-beta3 / s3cmd-1 .1.0-beta3.zip$ unzip s3cmd-1.1.0-beta3.zip$ cd s3cmd-1.1.0-beta3$ python setup.py install# s3cmd 설정 ( "Access Key"액세스 키 ID를 지정 'Secret Key'에서 비밀 키를 지정)$ s3cmd --configure |
백업을 수행하는 쉘 스크립트
Amazon S3에 백업을 수행하기 위해 다음의 내용으로 쉘 파일을 만들고 실행한다. 아래의 예에서는 Amazon S3에 3 일분의 백업 데이터를 저장하고 로컬로 백업 데이터는 남기지 않게하고있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | $ vi backup.sh############################! / bin / sh# 며칠 분 저장하거나period = 3# 로컬 백업 저장 디렉토리backupdir = / usr / local / backup# 백업의 이름today =` date + % Y % m % d ' `# web 디렉토리webdir = / var / www# MySQL 호스트 이름dbhost = localhost# MySQL 사용자 이름dbuser = hoge# MySQL 비밀번호dbpasswd = xxxxx# Amazon S3 버킷 이름backet = example# Amazon S3 백업 저장 디렉토리s3backupdir = backup# 로컬 백업 데이터를 저장mkdir $ backupdir / $ todaytar cvfz $ backupdir / $ today / www . tar .gz $ webdir# mysql 데이터를 저장/ usr / local / bin / mysqldump -A -h $ dbhost -u $ dbuser -p $ dbpasswd --opt --default-character- set = binary | gzip > $ backupdir / $ today / mysql .sql.gz# Amazon S3에 전송# / usr / local / bin / ruby / home / 계정 이름 /s3sync/s3sync.rb (벚꽃의 렌탈 서버의 경우)ruby / usr / local / s3sync / s3sync .rb -r --delete $ backupdir / $ today $ backet : $ s3backupdir# 로컬 백업 데이터를 삭제rm -rf $ backupdir / *# Amazon S3에서 오래된 파일을 삭제# yesterday =`date -v - $ {period} d + % Y % m % d` (벚꽃의 렌탈 서버의 경우)yesterday =` date -d "$ period days ago" + % Y % m % d ' `# / home / 계정 이름 / local / python / bin / s3cmd (벚꽃의 렌탈 서버의 경우)/ usr / bin / s3cmd del -r s3 : // $ backet / $ s3backupdir / $ yesterday // usr / bin / s3cmd del -r s3 : // $ backet / $ s3backupdir / $ yesterday###########################$ chmod 700 backup.sh |
해당 자료는 서치중에 일본 사용자가 작성한 부분을 가져왔습니다.
번역 되어있기때문에 명령어 부분의 뛰어쓰기는 인지하고 작업해주시기 바랍니다

아 맞다 내 블로그 복사안되지.. 방법 많잔아요...ㅋㅋ
명령어 부분은 아래의 이미지에서 체크하여 주시기 바랍니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # rubyのインストール$ sudo yum install ruby# s3syncをダウンロード・解凍$ wget http://s3.amazonaws.com/ServEdge_pub/s3sync/s3sync.tar.gz$ tar zvfx s3sync.tar.gz# configファイルを作成# s3config.ymlの場所は、環境変数・$S3CONF/・$HOME/.s3conf/・/etc/s3conf/ のいずれか$ sudo mkdir /etc/s3conf/$ sudo cp s3sync/s3config.yml.example /etc/s3conf/s3config.yml$ sudo vi /etc/s3conf/s3config.yml##############################aws_access_key_id: xxxxx # アクセスキーIDを記述aws_secret_access_key: xxxxx # シークレットアクセスキーを記述S3SYNC_NATIVE_CHARSET: UTF-8AWS_CALLING_FORMAT: SUBDOMAIN # リージョンが米国以外の場合は必要############################## |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # yumでインストールの場合$ cd /etc/yum.repos.d/$ wget http://s3tools.org/repo/RHEL_6/s3tools.repo$ sed -i -e s/enabled=1/enabled=0/ s3tools.repo$ yum install s3cmd --enablerepo=s3tools# zipファイルをダウンロードしてインストールの場合(pythonが必要)$ mkdir -p $HOME/local/python$ wget http://peak.telecommunity.com/dist/virtual-python.py$ python virtual-python.py --prefix=$HOME/local/python -v$ vi .cshrc############################### 以下を追記set path = ($HOME/local/python/bin $path)set PYTHONPATH =($HOME/local/python)############################### .cshrc再読み込みのため、一旦ログアウトしてログイン$ wget http://peak.telecommunity.com/dist/ez_setup.py$ python ez_setup.py$ wget http://downloads.sourceforge.net/project/s3tools/s3cmd/1.1.0-beta3/s3cmd-1.1.0-beta3.zip$ unzip s3cmd-1.1.0-beta3.zip$ cd s3cmd-1.1.0-beta3$ python setup.py install# s3cmdの設定(「Access Key」でアクセスキーIDを指定、「Secret Key」でシークレットアクセスキーを指定)$ s3cmd --configure |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | $ vi backup.sh############################!/bin/sh# 何日分保存するかperiod=3# ローカルのバックアップ保存ディレクトリbackupdir=/usr/local/backup# バックアップの名前today=`date '+%Y%m%d'`# webディレクトリwebdir=/var/www# MySQLホスト名dbhost=localhost# MySQLユーザ名dbuser=hoge# MySQLパスワードdbpasswd=xxxxx# Amazon S3バケット名backet=example# Amazon S3バックアップ保存ディレクトリs3backupdir=backup# ローカルにバックアップデータを保存mkdir $backupdir/$todaytar cvfz $backupdir/$today/www.tar.gz $webdir# mysqlデータを保存/usr/local/bin/mysqldump -A -h$dbhost -u$dbuser -p$dbpasswd --opt --default-character-set=binary | gzip > $backupdir/$today/mysql.sql.gz# Amazon S3に転送# /usr/local/bin/ruby /home/アカウント名/s3sync/s3sync.rb(さくらのレンタルサーバーの場合)ruby /usr/local/s3sync/s3sync.rb -r --delete $backupdir/$today $backet:$s3backupdir# ローカルのバックアップデータを削除rm -rf $backupdir/*# Amazon S3から古いファイルを削除# yesterday=`date -v-${period}d +%Y%m%d`(さくらのレンタルサーバーの場合)yesterday=`date -d "$period days ago" '+%Y%m%d'`# /home/アカウント名/local/python/bin/s3cmd(さくらのレンタルサーバーの場合)/usr/bin/s3cmd del -r s3://$backet/$s3backupdir/$yesterday//usr/bin/s3cmd del -r s3://$backet/$s3backupdir/$yesterday###########################$ chmod 700 backup.sh |
참조 URL :
http://2inc.org/blog/2013/02/03/2639/
http://blog.csdn.net/for_tech/article/details/51098251
'IT 이야기 > AWS' 카테고리의 다른 글
| AWS CLI와 아마존 S3에 대용량 파일을 업로드 (0) | 2016.04.21 |
|---|---|
| AWS Security Credentials 설정및 EC2 <-> S3 연동(log/backup) (0) | 2016.04.20 |
| Collecting Logs into Elasticsearch and S3 (0) | 2016.04.20 |
| AWS_CN 운영과정 - 1 (0) | 2016.04.20 |
| fluentd (td-agent)의 설치 및 설정 (업데이트중) (0) | 2016.04.19 |